Working with the best in eCommerce






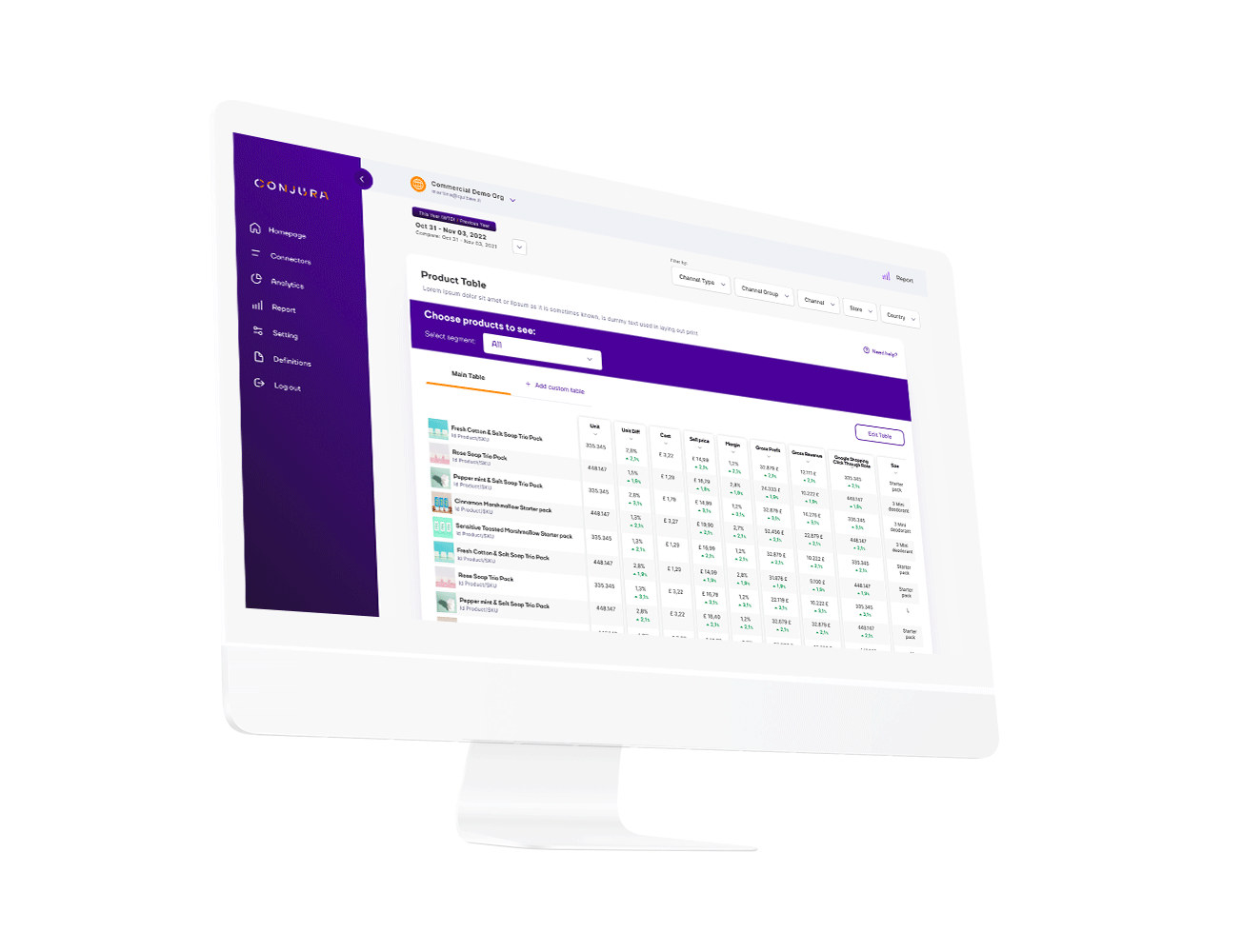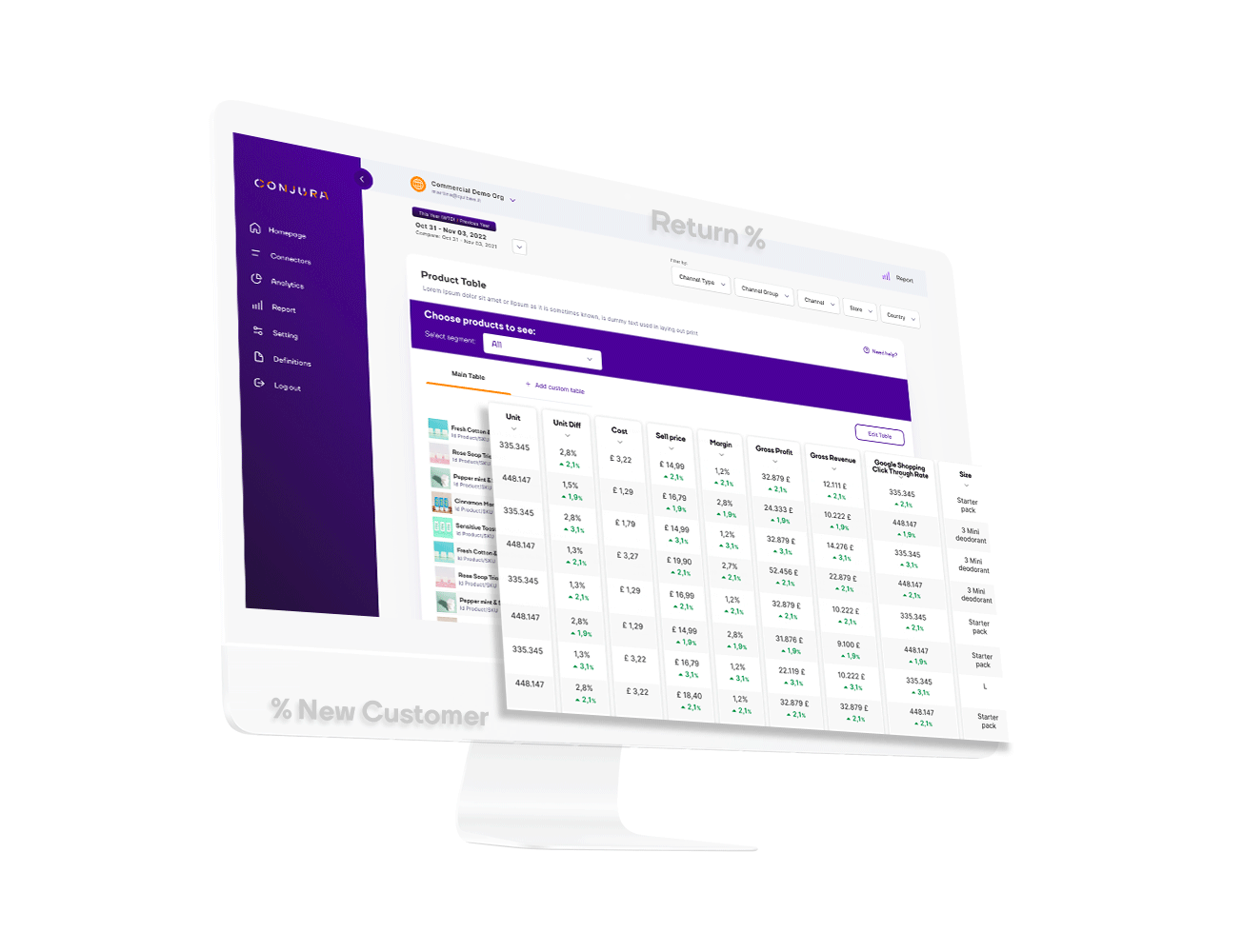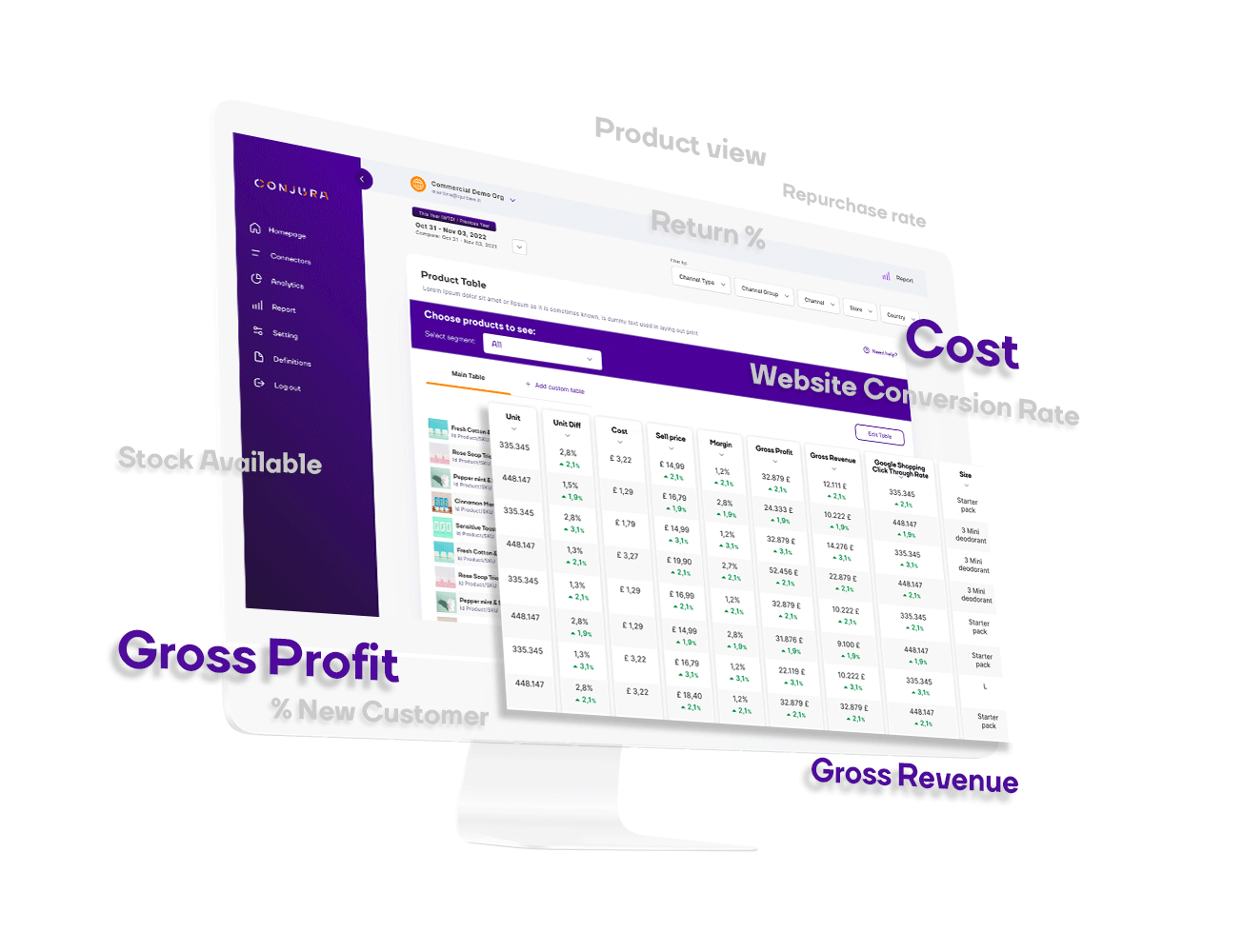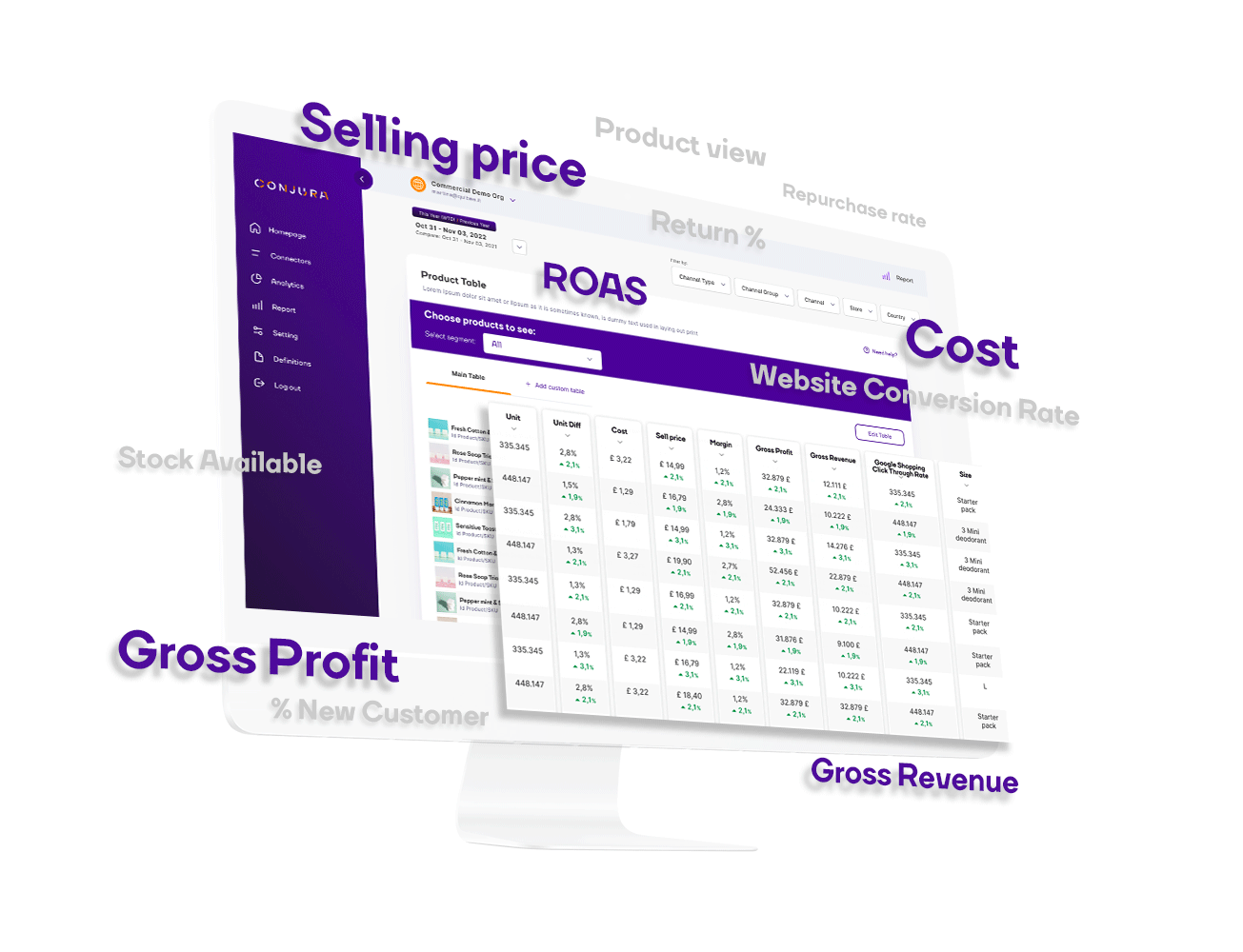
Access metrics such as Contribution Margin, Gross Profit Margin, New vs Existing Customer %, LTV to CAC ratio.
Want more detail - simply click on a metric and explore.
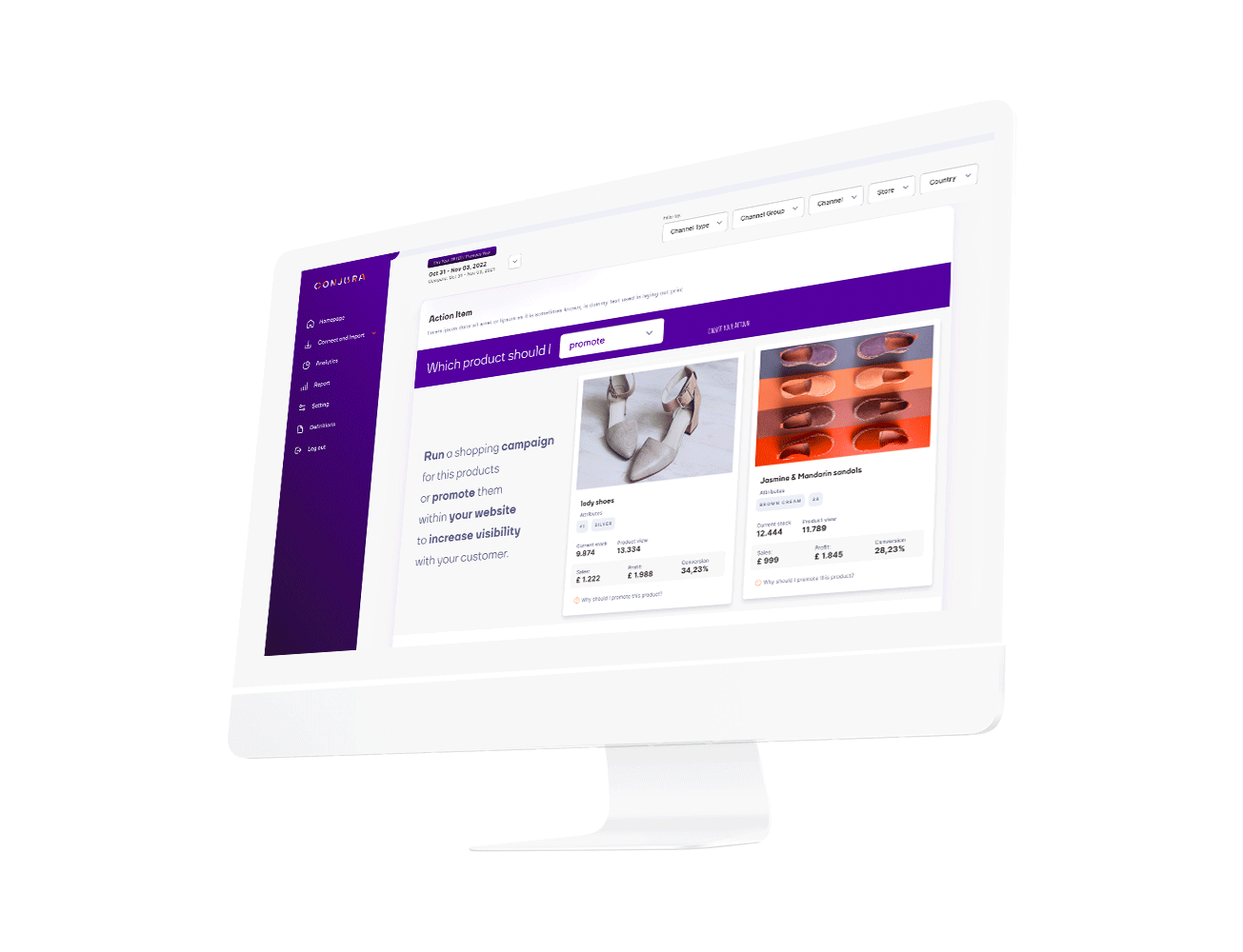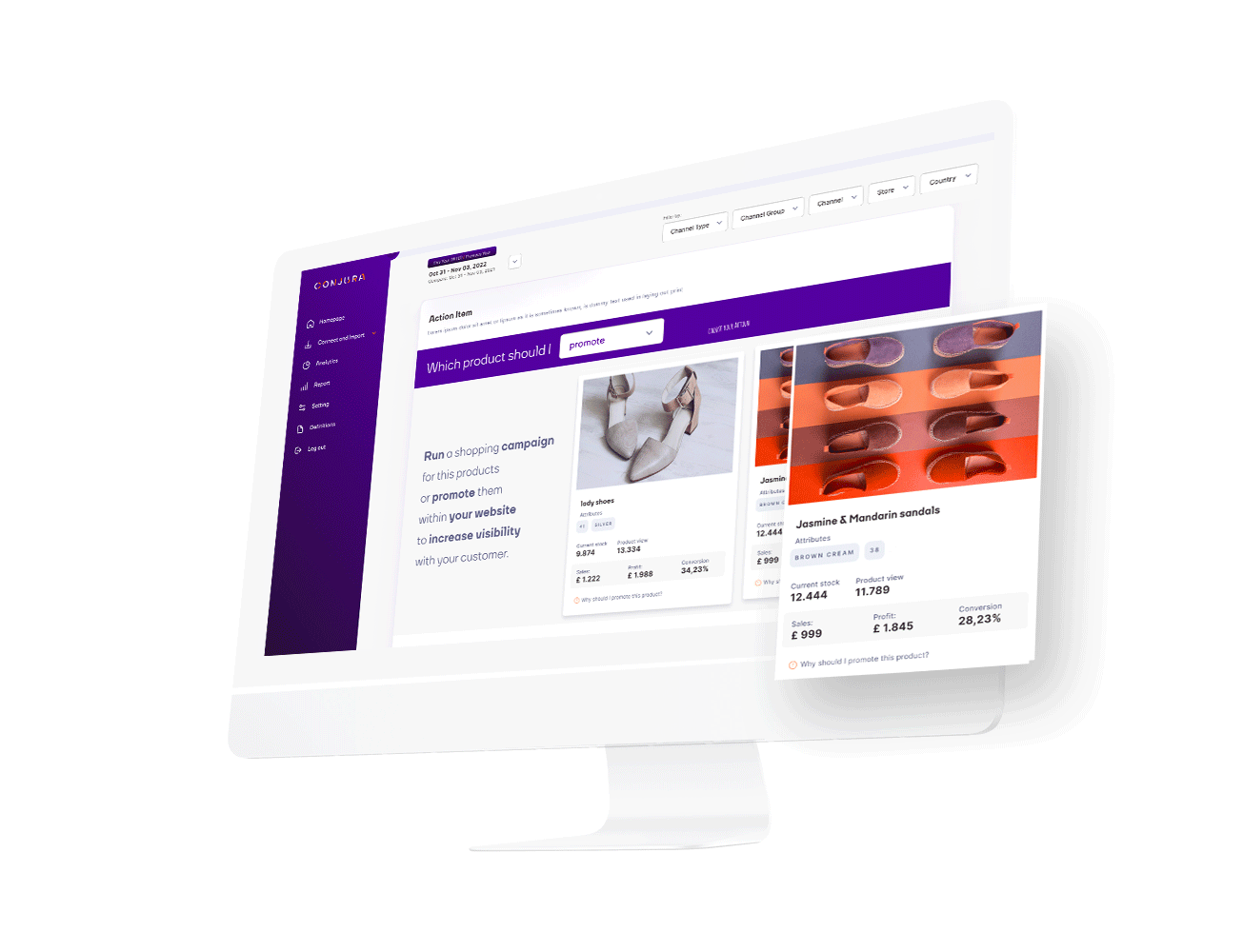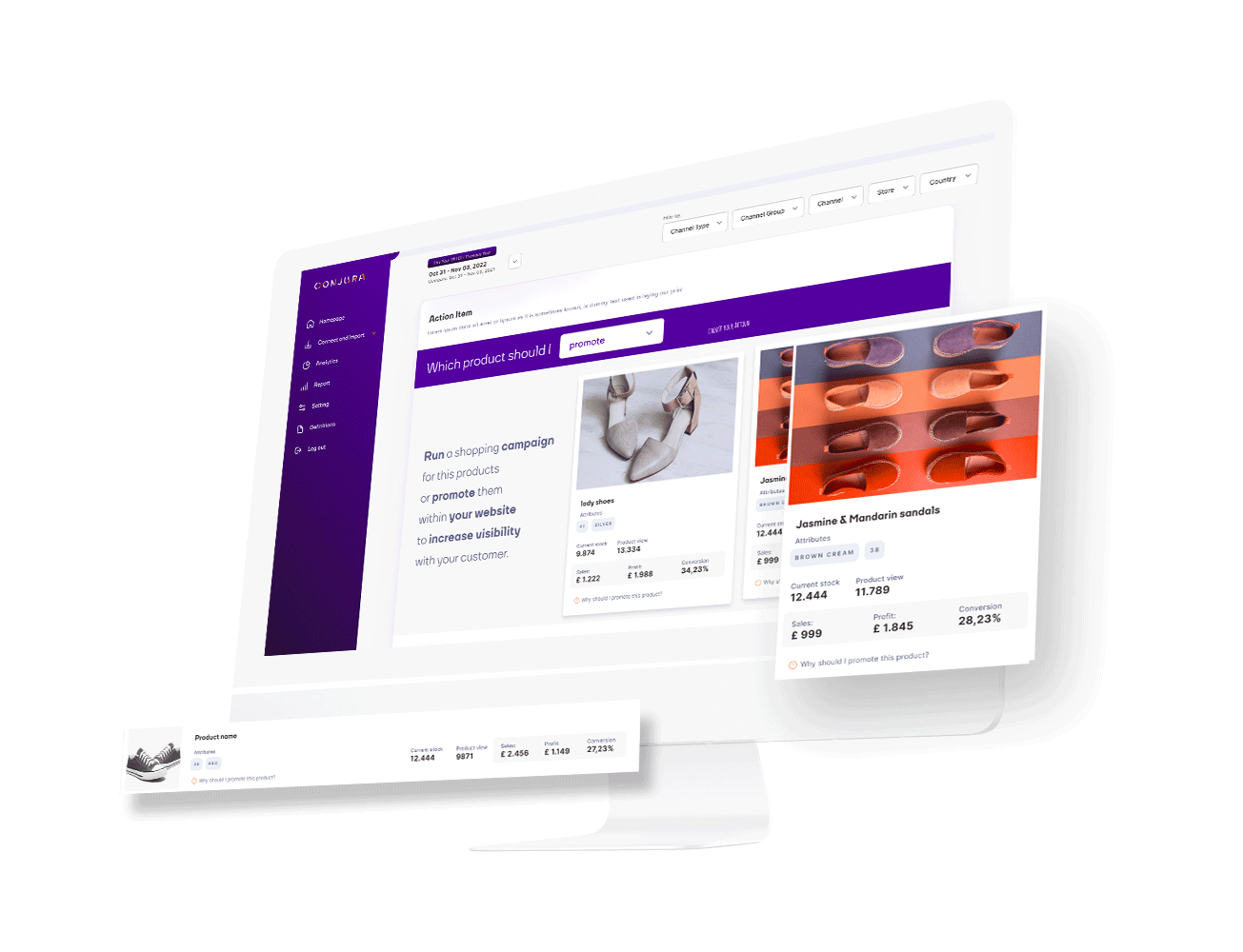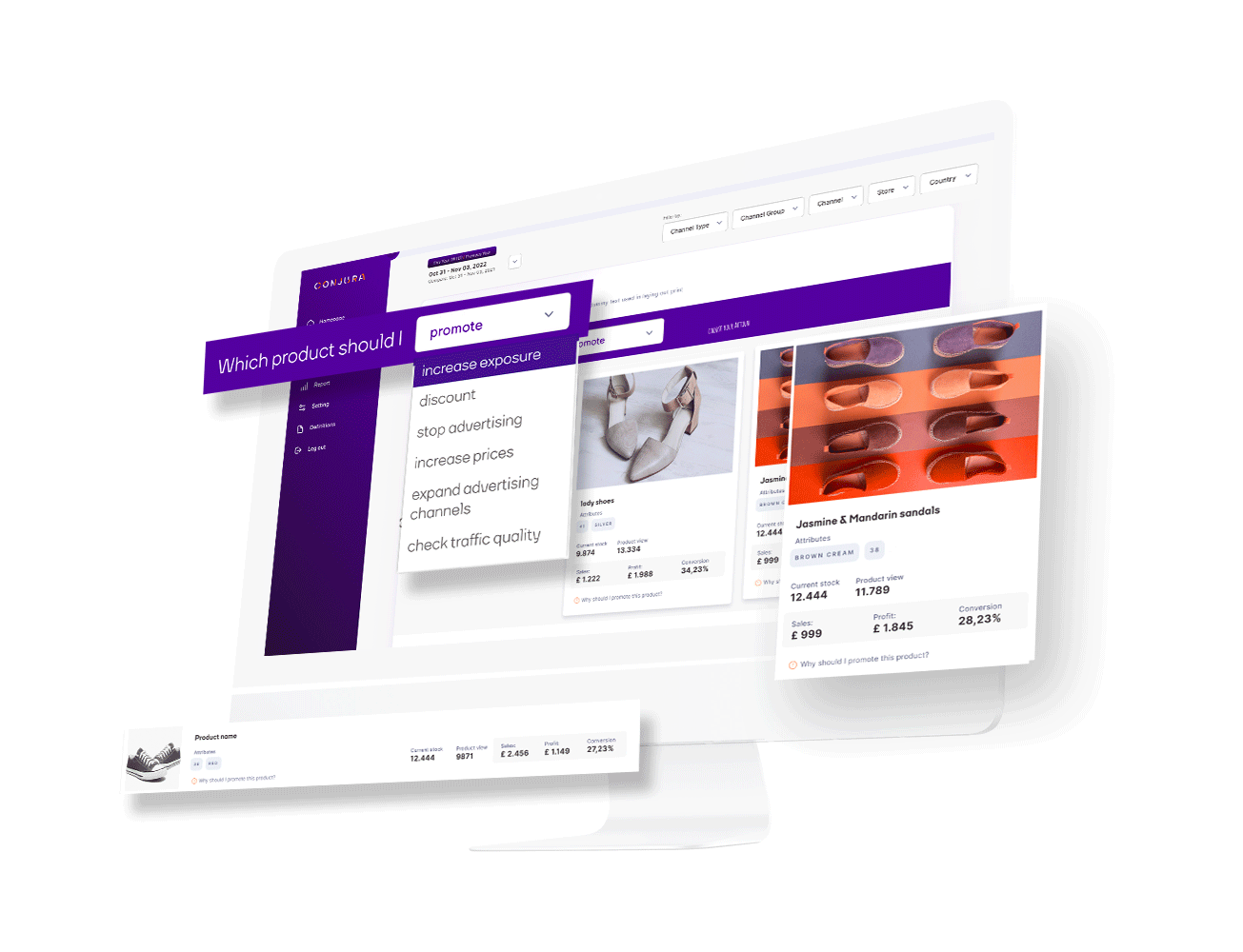
Identify your best performing products that customers love and learn the reasons why other products are underperforming.
Our recommendations remove the need for guesswork.